RabbitMQ 튜토리얼 살펴보기 (2) - Work Queues
11 Feb 2022Work Queues
-
Prerequisites
- RabbitMQ
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.9-management- python client
- 가상환경을 만들고 라이브러리 설치
python -m venv venv source venv/bin/activate (venv) pip install pika
두번째 튜토리얼에서는 시간이 많이 걸리는 작업을 여러 작업자에게 분산하는데 쓰이는 작업 큐를 만들어본다. task queue라고도 불리는 작업 큐의 기본 바탕은 리소스에 중심되는 작업을 즉시 수행해서 완료될 때까지 기다려야 하는 것을 피하는 것이다. 수행할 작업을 메세지로 캡슐화해서 큐에 보내면 백그라운드에서 실행중인 worker가 작업을 가져와서 수행하게 된다. 작업자가 많을 경우에는 작업을 공유하게 된다.
예제에서는 복잡한 작업을 time.sleep()으로 대체해서 컨슈머에서 실행하도록 한다. Hello world 예제의 send.py처럼 new_task.py에 퍼블리셔를 추가한다. 여기에서는 파이썬 명령 인자값이 없으면 Hello world!를 있으면 인자값을 받아서 메세지를 보내도록 했다. 그 외에는 커넥션, 채널, 큐를 생성하고 메세지를 퍼블리싱 하는 부분은 처음 튜토리얼과 동일하다.
# new_task.py
import sys
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
message = ''.join(sys.argv[1:]) or 'Hello world!'
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message)
print('sent message')
connection.close()
작업자 역할을 하는 컨슈머에서는 콜백 함수에서 복잡한 작업에 해당되는 time.sleep()이 추가된다. 만약 python new_task.py hi....로 보내게 된다면 4초 후에 done이 출력된다.
# worker.py
import time
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(f'received {body.decode()}')
time.sleep(body.count(b'.'))
print('done')
channel.basic_consume(queue='task_queue', on_message_callback=callback)
print('wating for messages')
channel.start_consuming()
Round-robin
작업 큐를 사용하면 병렬 작업을 쉽게 할 수 있다. 위에서 만든 작업자를 더 추가하면 쉽게 확장할 수 있다. 터미널에서 worker.py를 2개를 실행해서 new_task.py로 메세지를 보내는 작업을 해봤다. 시간이 오래 소요되도록 인자값에 … 을 많이 추가했더니 기다리는 시간이 좀 걸리긴 했지만 두 개의 컨슈머에서 번갈아가면서 메세지를 가져와서 실행하는 것을 확인할 수 있었다. 기본적으로 rabbitMQ는 각 메세지를 다음 컨슈머에게 보내므로 컨슈머는 평균적으로 같은 수의 메세지를 받게 된다. 이런 배포 방식을 round-robin이라 한다.
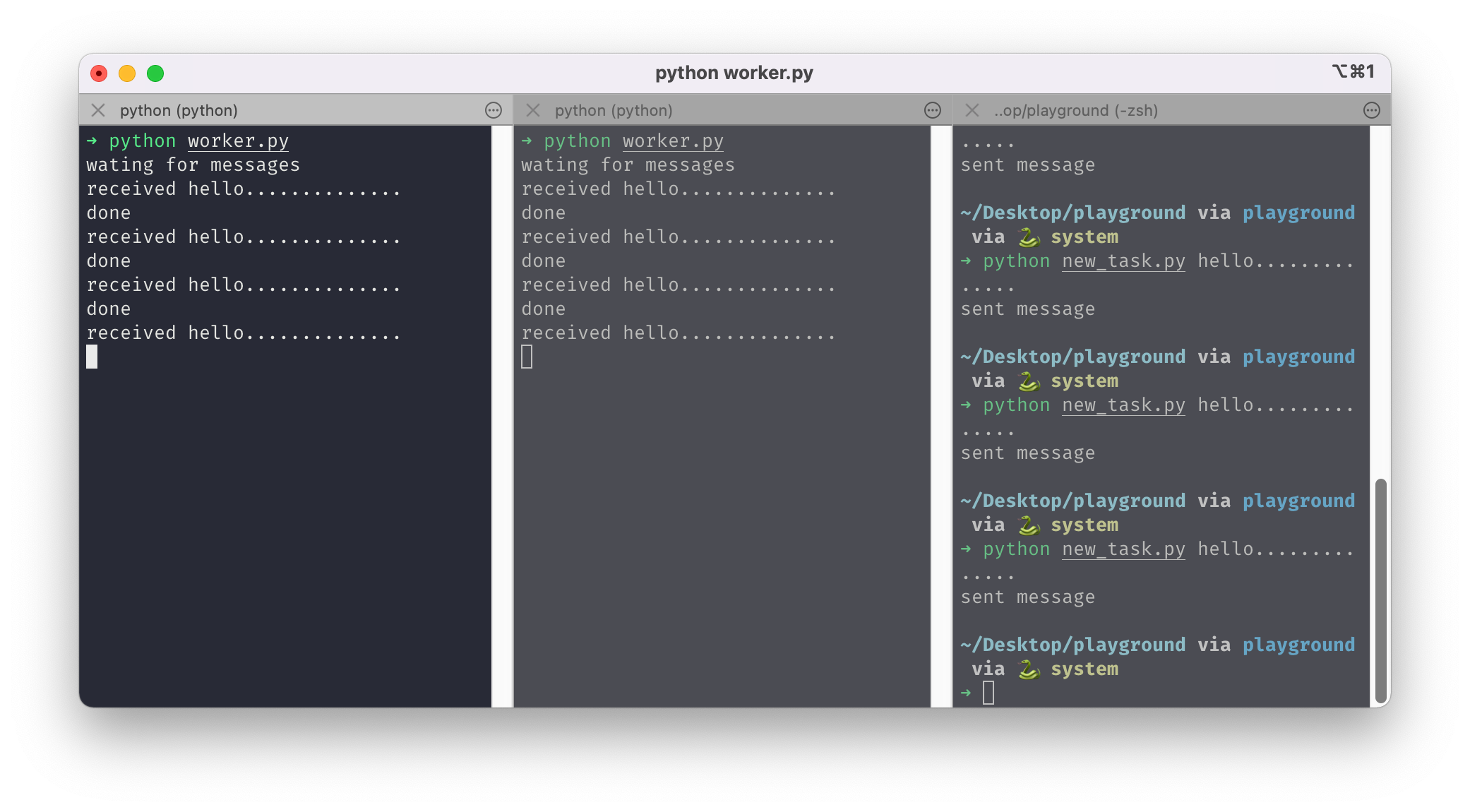
메세지 확인
위의 코드에서는 메세지가 컨슈머에게 전달되면 바로 삭제 표시를 하게 된다. 이런 경우에서는 작업자를 죽이게 되면 처리한 메세지를 잃게 된다. 이 작업자에게 발송되었지만 작업되지 않은 메세지 또한 당연히 잃게 된다. 작업자가 죽었을 때 메세지가 다른 작업자에게 전달되면 이런 상황을 막을 수 있다.rabbitMQ에서는 메세지 확인 기능을 제공한다. 컨슈머에서 메세지를 받고 처리하게 되면 rabbitMQ에 ack가 보내져서 특정 메세지가 수신되고 처리되었음을 전달해 삭제해도 된다는 것을 알려준다.
만약 채널이나 연결이 닫히거나 혹은 TCP 연결이 끊어져 컨슈머가 ack를 보내지 못하고 죽게 되면, rabbitMQ에서는 메세지가 완전히 진행되지 않은 것을 알고 다시 큐에 넣게 되며 다른 컨슈머가 있다면 다른 컨슈머에게 전달된다. 이런 방법으로 메세지 손실을 방지할 수 있다.
기본적으로 수동 메세지 확인이 설정되어 있으며 hello world 튜토리얼에서는 auto_ack=True 값으로 설정을 해제했었다. 이번에는 컨슈머가 작업을 완료하면 적절한 ack를 보내도록 코드를 수정해보도록 한다.
ch.basic_ack(delivery_tag=method.delivery_tag)에서 작업을 완료하고 ack를 보내도록해 컨슈머가 죽을지라도 확인되지 않은 메세지가 다시 전달되도록 한다. ack는 메세지를 받은 동일한 채널에서만 보내져야 하며 다른 채널을 통해 메세지 확인을 하도록 할경우에는 채널 수준의 프로토콜 예외가 발생하게 된다.
def callback(ch, method, properties, body):
print(f'received {body.decode()}')
time.sleep(body.count(b'.'))
print('done')
ch.basic_ack(delivery_tag=method.delivery_tag)
메세지 내구성
컨슈머가 죽더라도 메세지를 잃지 않는다. 그렇다면 rabbitMQ 서버가 멈출 때는 어떨까? rabbitMQ가 멈추거나 충돌이 있다면 설정을 하지 않는 한은 큐와 메세지를 모두 잃게 된다. 그러므로 메세지와 큐 모두 손실되지 않도록 durable 설정이 필요하다.
먼저 큐를 만들 때 설정을 해주도록 한다. 처음에 만들었던 hello라는 큐는 내구성 설정이 되어 있지 않은 상태에서 만들어져서 내구성 여부를 추가해도 작동하지 않으므로 task_queue라는 새로운 큐를 만들고 durable=True 설정을 해주도록 한다. 컨슈머에도 똑같이 하도록 한다.
channel.queue_declare(queue='task_queue', durable=True)
그리고 rabbitMQ가 재시작 된다해도 큐를 잃지 않도록 퍼블리싱할 때 설정을 추가해줄 수 있다. delivery_mode 값에 PERSISTENT_DELIVERY_MODE를 넣어주도록 한다.
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = pika.spec.PERSISTENT_DELIVERY_MODE
))
공정한 분배
큐와 메세지를 안정적으로 유지할 수 있는 설정을 추가했다. 이제 메세지 상황을 좀 더 구체적으로 가정해볼 때, 무거운 메세지와 가벼운 메세지가 번갈아 퍼블리싱 되고 두 개의 컨슈머가 이 작업을 처리한다고 하면 하나의 컨슈머만 무거운 메세지를 처리하게 될 것이다. 결국 한 쪽만 바쁘고 한 쪽은 간단한 작업만 수행하는 모습이 될 것이다. 이런 상황을 방지하기 위해 prefetch_count를 설정할 수 있다. basic_qos 메서드를 통해 한 번에 하나의 컨슈머에게 두 개 이상의 메세지를 보내지 않도록 한다. 이렇게하면 컨슈머가 이전 메세지를 처리하고 ack를 보내기 전까지는 새 메세지를 보내지 않고 다른 컨슈머에 보내게 된다.
channel.basic_qos(prefetch_count=1)